2022年の振り返り
すっかりブログを書かなくなってしまいましたが,2022年の振り返りです.
仕事
国際的大規模イベント
今年はなんといっても某大規模イベントの準備に追われた一年でした.主に負荷対策・障害対策・攻撃対策を担当していました.時間が限られる中でいかに必要な対策を的確に積み重ねていくか,難しい場面も多くありましたが,最終的には無事何事もなく放送を完遂することができて嬉しく思います.
技術戦略
その反面,技術的な改善については改善するべき事項の洗い出しと優先順位付けをするにとどまり,実際の改善に対してなかなか時間を取ることができませんでした.
年明けからは全社的にも開発速度・開発生産性の向上をプロジェクトとして進めていくことが決まっており,その流れにも乗って実質的な成果が生み出せるように尽力していきたいです.
対外発信
去年は自らが対外発信をする機会が多かったですが,今年は対外発信の場を作ることに注力し,Muddy Web というブランドで Meetup と Podcast を定期的に行う体制を作ることができました.来年は会社からの技術発信がさらに盛り上がるように,引き続き活動していければと思います.
Muddy Web 始まりました! #muddy_web https://t.co/CItoOvOvbe
— nodaguti (@nodaguti) 2022年10月11日
Web フロントの新しい Podcast を始めました!
— nodaguti (@nodaguti) 2022年11月16日
隔週で公開していく予定なので,ぜひ聴いていただけると嬉しいです 🙌 https://t.co/Q4yLTpXA1q
プライベート
スキー
今年は年明けにいったニセコが初滑りでした.
— nodaguti (@nodaguti) January 5, 2022
今日はよく晴れてて、滞在中初めて山頂のリフトが動いた pic.twitter.com/9EYeXgZA49
— nodaguti (@nodaguti) January 6, 2022
また,2022年1月下旬から2月下旬にかけての1ヶ月間,旭川に滞在して平日は仕事をしつつ,休日はスキーに勤しむ日々を送っていました ⛷
都市に滞在しながらスキー場まで無料送迎があるという最高の環境でした.
☀️⛷ pic.twitter.com/ET2LYqhxNM
— nodaguti (@nodaguti) 2022年1月22日
— nodaguti (@nodaguti) 2022年1月23日
夜景が綺麗だった! pic.twitter.com/nTUVlCdr2u
— nodaguti (@nodaguti) 2022年1月29日
スキーのためという目標ができたことでジムも続けられているので,今シーズンも楽しんでいきたいです.
マイル修行
3-6月にかけて JAL マイル修行 (JGC 修行) を行い,毎土曜日に羽田と那覇を往復する生活(那覇滞在時間1時間)を送っていました.

昨日の修行で石垣島から仕入れてきたヤギ汁を飲んでみた (人生初)
— nodaguti (@nodaguti) 2022年5月22日
すごい匂いだけどコーレーグースー入れたらそれなりにいける感じに
もう何回か食べたらはまるかもしれない pic.twitter.com/PvBgiJlFvc
ダイビング
夏にできるアクティビティをということで,ダイビングのライセンスを取得しました 🤿
Advanced Open Water Diver のCカードが届いて、30mまで潜れるようになった 🎉 pic.twitter.com/T7a1wuzg0V
— nodaguti (@nodaguti) 2022年12月24日
勝手に結構時間がかかるものだと思い込んでいたのですが,実は都心から2時間ちょっとの川奈で3日間講習を受けると取得できるというもので,楽しみながらスキルを習得できました.
2023年に向けて
ここ数年は業務で MTG に追われていたり目の前のタスクに忙殺されたりという状況が続いていて,じっくり腰を据えて価値を生み出すことができていませんでした.2023年は周りの期待・評価に見合うだけの成果を出せるよう頑張っていきたいです.
2021年の振り返り
今年は年賀状を作るのをやめようと考えているので,代わりに振り返り記事というものを書いてみようと思います.
テックリード就任
2019~2020年にかけて Web チームを技術的にリードする人が不在の時期が続いてしまい,弊害が無視できなくなってきたということで,CTO とチームリーダーから打診されて2021年1月に Web チームのテックリードに就任しました.
業務を兼務しすぎたことと自身の能力不足もあって今年はまだチームをリードできているとは言い難い状態で,反省点も数多くあります.来年は関わっている業務の整理や委譲をもっと進めて,チームが必要としている領域によりフォーカスして貢献できるよう,セルフマネジメント力を高めていきたいです.
対外活動
ほとんどアウトプットできなかった2020年と異なり,今年は気がついたらさまざまな対外活動をした1年になりました.
Web24
GW に Web24 という Web の話を24時間議論するイベントがあり,パフォーマンスのセッションオーナーとしてお誘いいただきました.
nodaguti.hatenablog.com togetter.com
アーカイブがないので今となっては何を話したのかわからないですが,公の場で登壇形式として初めてパフォーマンスの話をすることができました.
CA BASE NEXT
5月末には会社の若手が運営する技術カンファレンス CA BASE NEXT でパフォーマンスと信頼性について登壇しました.
3月くらいからパフォーマンスに加えて本格的にクライアント領域での SRE 活動に取り組み始めたので,両方の話について取り組みのアプローチを紹介する構成にしました.
結果として盛り込みすぎになってものすごく早口になってしまったのが反省点です.
WEB+DB PRESS
会社として連載を受け持つことになり,その中の一回として8月の Vol.124 でパフォーマンスの記事を寄稿しました.
パフォーマンスの定義と重要性,そしてデータドリブンに改善を進める方法について ISO 25000 や SLI/SLO を絡めつつ概観する内容に仕上がりました.
パフォーマンスに関して Core Web Vitals の普及や各種ツールの進化が進む中で,「なぜパフォーマンスに取り組むのか?」「どうやって改善を進めるのが王道なのか?」を改めて自分の中で整理するよい機会となりました.
ABEMA Developer Conference
12月に ABEMA として3年ぶりに開催されたテックカンファレンス ABEMA Developer Conference 2021 では,Web チームからパフォーマンスの取り組みにフォーカスしたセッションを行いました.
CA BASE NEXT での失敗を生かして内容を詰め込みすぎず,それでいて CA BASE NEXT と WEB+DB PRESS での話題を双方盛り込んだ 2021 年の集大成的なセッションにすることができました.
結果として今年はパフォーマンスに関するアウトプットを多くした一年になりましたが,来年はテックリードとしてより広い視野でのアウトプットを増やせるようになりたいです.
プライベート
引越し
年明けからメンタルの調子を崩してしまい,狭くて暗い部屋に一因があると考えて 1R から 1K に引っ越しました.
17㎡ → 26㎡ に引っ越しました
— nodaguti (@nodaguti) February 22, 2021
設備が充実してて文化的な生活を営める気配を感じる 🙌
— nodaguti (@nodaguti) February 22, 2021
カーテン留め用の金具が付いてるとか、玄関脇に下駄箱があってその上に物が置けるとか、細かいところで感動しちゃう 🤗
それまでは狭すぎてダイニングテーブルが物置になったり,ディスプレイを電子レンジの上において仕事をしたりしていましたが,引越し後は陽当たりがとてもよく,風呂トイレ別で非常に快適になりました.
そのおかげもあってか年の後半は回復して運動を再開したり旅行に行ったりできるようになり,健康的な生活を送れるようになったのがよかったです.やはり人間には太陽が大事.
旅行
遠出をせずに旅行気分を楽しめる方法として都内のラウンジ付きホテルに2回泊まりました.
- ホテルニューオータニ
- ヒルトン東京
どれもおしゃれで美味しかった
— nodaguti (@nodaguti) November 22, 2021
健康を考えず限界まで食べたのでベッドでダウンしてる pic.twitter.com/myVUonlaZE
また,就職してから始めた百名湯巡りの一環として石川県の片山津温泉に行きました.北陸に泊まること自体が初めてで,金沢の独特な文化を堪能できて楽しい旅行でした.
片山津温泉 森本 → 金沢 御宿 野乃 で最高だった pic.twitter.com/8fSAS02Vuy
— nodaguti (@nodaguti) October 19, 2021
来年はスキー板を買ったのでスキーに行く回数を増やすのと,JGC 修行をする計画を立てているのでとりあえず年前半は羽田と那覇を往復する生活をする予定です.
My new gear... pic.twitter.com/PzqI5OYKEX
— nodaguti (@nodaguti) October 5, 2021
2022年に向けて
さまざまなことを着実に進めつつ,視野と見識をさらに広げる一年としたいです.みなさまよいお年を!
「質とスピード」と SHIROBAKO
この記事は SHIROBAKO Advent Calendar 2021 の22日目です.
SHIROBAKO 7話で原画がなかなか仕上げられずに悩んでいる絵麻に対して,杉江さんは次のように声をかけます.
絵麻「うまくなれば速く描けるようになるんじゃないんですか?」
杉江「速く描くにはうまくなる.うまく描くにはいっぱい描く.いっぱい描くには速く描く.技術とスピードは実は全く別の問題でね」
これを聞いて,杉江さんの「技術とスピード」という言葉は IT 業界でよく話題に挙がる「質とスピード」の関係と似ていそうだと気が付きました.
ソフトウェア開発の現場では「品質とスピードはトレードオフの関係にある」という考え方,すなわち品質を高めようとすれば開発に時間がかかり,品質を犠牲にすれば短時間でソフトウェアを完成させられるという考え方がよく信じられています.
しかし,実際には品質(特に保守性)が高ければスピードは上がり,スピードが速ければ仮説検証サイクルが多く回せるのでプロダクトの質が高まるという関係になっていること,そしてこの二つと真にトレードオフになっているのは教育であるということが事例研究や経験によって明らかになっています.
つまり,人材育成や技術調査といった「未来への投資」を行うかどうかが,品質 および スピードに影響するということです.
数年前に,教育コストを削減するためにジュニアエンジニアを採用せず,経験者(シニアエンジニア)だけでチームを構成しようとしている会社は次第にエンジニア組織が弱っていき,開発速度もソフトウェアの品質も上がらなくなるという話が話題になりました.これもまさに,教育と「品質およびスピード」がトレードオフの関係であることを示す好例といえるでしょう.
さて,SHIROBAKO の話に戻ると,冒頭の杉江さんの言葉を聞いた絵麻は,まさに質とスピードをトレードオフと捉え,質を犠牲にすることで速度を出そうとします.その結果,瀬川さんから「描き急いでいるせいで,全部の線がなんとなくでとりあえず」(7話) になっていると指摘され,全カットリテイクになってしまいました.
そのあとも丁寧さとスピードの狭間で悩み続ける絵麻でしたが,見かねた井口さんから「『まなぶ』って言うのは『まねぶ』っていうじゃん?みんな最初は誰かの真似.おんなしおんなし」 (8話) と周りのうまい人の技術を吸収して経験を増やすことの大切さをアドバイスされ,原画完成への希望が湧いてくるのでした.
なお,杉江さんも「技術とスピード」の話のときに「周りにうってつけの手本がいる.小笠原さんや井口さん,彼女らも安原さんと同じ壁を乗り越えてきたのだから,相談にのってもらえればいい」(7話) と先輩から技術を学ぶことを提案しています(残念ながらこのときの絵麻には響きませんでしたが).
作中で絵麻は優しい先輩からアドバイスと「秘密の並木道」を教えてもらって復活し,最終的に劇場版では作画監督を務めるまでになりました.しかし,これが能力・経験至上主義の現場であれば首を切られてしまい,絵麻個人としても武蔵野アニメーションという組織としても成長の機会を失ってしまっていたことでしょう.
SHIROBAKO のこのエピソードは,原画担当になったばかりの絵麻といういわばジュニアエンジニアのような立ち位置のメンバーに対して,組織として教育に投資をすることが重要だということを示唆しているように思います.
先行研究
過年度の記事
星野リゾート OMO7 旭川で2週間ワーケーションをした話【2020年】
去年(2020年)の話になりますが, 伊豆大島に引き続き,旭川でも2週間ワーケーション(リモートワーク+観光)をしてきたのでどんな感じだったのか紹介します.
使用したプラン(今年も実施中!)
使ったプランは,星野リゾートの都市観光ホテル OMO7 旭川が提供していた「憧れのリモート書斎プラン」です.これは15〜30連泊限定で素泊まり1泊3000円になる格安プランだったので,今回は最低泊数の15泊16日で申し込みました.
さらに予約後に GoTo トラベル対象にもなったので,実質的に一泊1500円弱で泊まることができました!

このリモート書斎プランですが,なんと今年も継続して提供されています.
しかも7泊からでも OK と使い勝手が向上しています.予約サイトの表示によると残念ながら今年のプランは初めから「GoTo トラベル対象外」と明記されていますが,それでも充分お得なプランだと思います.
OMO7 旭川では「スキー都市宣言」として近隣へのスキー場へ無料送迎バスを出すなど,ウィンタースポーツへのサポートも充実させているので,平日は仕事をして休日はスキーを楽しむという滞在はいかがでしょうか?
出発〜宿到着
今回が人生で初めての北海道でした.到着してから周辺の散策や買い出しなどを行いたかったため,余裕をもって AIR DO 83便 11:15 羽田発 12:50 旭川着の飛行機を選択しました.

空港に到着し,自動チェックイン機でチェックインをしようとしました(AIR DO に乗るのも初めてだったので,スキップサービスの存在に気がついていませんでした).
しかし,予約確認番号を入力して発券しようとするも「ご指定の航空券は見当たりません」というようなエラーが出て発券できません.2回,3回と試すも同じでした.
ここでふと時計を見ると,そこに表示されていた時刻は 11:10.予約した便の出発時刻を再度確認すると 11:15 でした.路線検索サイトで到着時刻を指定するつもりで出発時刻の欄に入力してしまい,空港に到着したときには保安検査場の通過時刻を過ぎてしまっていたのです!
すぐにカウンターの方に相談したところ,「まだ飛行機が出発していないので次の便に振替いたします」とのことで,17:15発18:50着の便に振り替えていただけました.今回はたまたま離陸前に気がつけましたが,もし離陸してしまっていたらと考えると背筋が凍りました... あのときのグラウンドスタッフの方,本当にありがとうございました.
意図せず6時間の待ち時間が発生してしまったので,ラウンジで本を読みつつひたすら時間を潰し,なんやかんやで来た飛行機に乗り,ようやく旭川空港に到着しました.


そこからさらにバスで1時間揺られ,20時に宿に到着しました.

部屋はスタジオルームという最も狭い部屋を選びましたが,コンパクトで機能的にまとまっていて充分快適でした.
仕事環境

部屋での仕事は,写真の手前にあるカウンターのようなテーブルですることになります.
PC だけなのでテーブルの広さはさほど問題になりませんが,ベッドに座ることになるので座面と床の高低差が小さくやや窮屈なこと,背もたれがないので長時間の作業にはあまり向かないことが難点かもしれません.私はよく壁に寄りかかって斜めに向いて作業していました.
また,テレビもかなり小さく,HDMI ケーブルを持っていきましたがサブディスプレイとしては使えないものでした.
一方で,一階のカフェスペースやラウンジは開放感があり快適な作業スペースでした.平日の昼間はほとんど人がいなかったため,会議がなければここでずっと作業することができました.無料ドリンクやお菓子も置いてあり,最高の環境でした!


インターネットは星野リゾートなだけあって高速な WiFi が全館完備されており快適でした.
また,OMO7 にはあの『サ道』にも掲載されているサウナプラトーが併設されており,仕事上がりに無料でととのうことができました.
浴槽や洗い場も広く,人も少なかったので気持ちよくリフレッシュできました.
食事
書斎プランは素泊まりなので,食事は自分で調達する必要があります.幸い OMO7 は市街中心地に近い好立地で,サツドラ (サッポロドラッグストアー)やイオンが徒歩圏内,繁華街の3・6街も近いので買い出しや外食には困りませんでした.


朝食
OMO7 の地下に電子レンジが設置されていたので,朝食はイオンで買ったパックごはんと納豆を食べていました.また,野菜不足を懸念して青汁の素を牛乳で割って飲んでいました.

到着翌日に買い物に行って,スーパーに大量の牛乳が並んでいるのを見て北海道を実感したりしていました.


昼食
お昼は歩いてすぐのところにある地元で有名な「七福弁当」というところによくお弁当を買いに行っていました.
中身は決まっておらず,予算と好みのおかずを伝えると店員さんがその日のおかずからいい感じにチョイスして作ってくれます.400-500円くらいでお腹いっぱいになれるのでとても嬉しいお店でした.

たまに旭川ラーメンを食べに行きました.


夕食
市内に1800店以上あるという飲食店を大いに満喫するべく,夕食は基本的に外食していました(もちろん一人,黙食,店員さんと会話するときは常にマスクを着用するなど感染対策はしっかり行っていました).
「ぎんねこ」さんで旭川名物新子焼きを食べたり


孤独のグルメにも出てきた「自由軒」でクリームコロッケを食べたり

ホッケと刺身で地酒を楽しんだり

本場のジンギスカンを堪能したり

旭川名物ホルモン焼きと道産サフォーク赤身肉の焼肉を食べたり


していました!
ちょうど「5・7小路ふらりーと」ではスタンプラリーを開催していて,足繁く通った結果3店舗のスタンプが集まり,なんと道産の新米真空パックセットがもらえてしまいました.商店街の方々ありがとうございました!

店舗の情報はホテルのロビーの大きな地図に紹介されていたほか,OMOレンジャーという地元ガイドの方と街巡りをして教えていただくことができ,たくさんの飲食店から迷わず美味しいお店をチョイスすることができました.

11月の旭川の気候
初めての北海道ということで寒さにはかなりビビっていましたが,11月は大体0度〜10度くらいと,東京の真冬と同じくらいでさほど寒くはありませんでした.東京の2月くらいと違ってわりあい薄着な周りの人を見ていると,次第にこちらも寒くないような気がしてくるから不思議でした.

滞在中一回だけ最高気温が0度近くまで冷え込み,雪が降ったことがありました.ロードヒーティングのおかげなのか凍りつくこともなく数日で溶けていきましたが,紅葉と雪が同居する幻想的な風景でした.


散歩・観光
宿から10分くらい歩いたところに,市のシンボルとして親しまれている「旭橋」があります.

ここからいつも石狩川に沿って遊歩道を散歩していました.

まだ雪が積もっていなかったので残念ながらペンギンのお散歩は見ることができませんでしたが,展示の方法や掲示物に工夫がされていておもしろかったです.



博物館では,関東の学校では学ぶことの少ないアイヌの方々について詳細に解説されていて,とても興味深く勉強になりました.

おわりに
立地の制約もありホテルに篭っていた伊豆大島と違い,旭川ではまさに暮らすように滞在しながら,仕事にグルメに観光にと街を思う存分味わうことができました.
今回は晩秋でしたが,真冬だと厳寒と雪で全く違う雰囲気の滞在となりそうです.スキー旅行を兼ねてぜひまたワーケーションしてみたいと思う体験でした!
Web24 というイベントで Web Performance に関する議論をします
Web のことをただひたすら 24 時間議論する
5/7 18:00 ~ 5/8: 18:00
登壇者の発言は個人のものであり所属する組織とは関係なし
というイベントです.その中の Performance セッションの情報はこんな感じ:
- 日時: 2021/05/08 11:10 - 12:40 (90分)
- Twitter ハッシュタグ: #web24_performance
- Togetter: https://togetter.com/li/1708710
私 (@nodaguti) はこの Performance セッションのセッションオーナーを Jxck さんから依頼されまして,一緒に議論をしたい!という方を選んで依頼をし,快諾いただけました.
twitter.com twitter.com twitter.com
Web に限らずブラウザエンジンやパフォーマンスのアカデミックな話題にも造詣が深い方・BtoB サービスのパフォーマンスチューニング経験がある方・クライアントだけでなくインフラやエッジを含めて総合的にパフォーマンス改善を進めている方など,バラエティに富んだメンバーが揃いました! 所属や詳しいバックグラウンドは当日も紹介を行わない予定なので,気になる方は Twitter から各自の情報を探ってみてください.
事前打ち合わせは避けるようアナウンスがあり,台本もないため当日どのような話になるのか私も想像がついていません.Core Web Vitals,事業の中でパフォーマンス改善を進める方法,パフォーマンスとはそもそもどのように計測するべきなのかなどいろいろな話題を議論できるのではと期待しています.
アーカイブも残らないことになっていますので,その場の生な議論をお楽しみいただければと思います.当日をお楽しみに!
ほかの登壇者のアナウンス
5/8 11:10-12:40 90分間 @nodaguti さん @saneyuki_s さん @shqld さんと Web におけるパフォーマンスを語りますhttps://t.co/M3AkTy5My8
— maxmellon / Kento TSUJI (@maxmellon_9039) May 4, 2021
webのperformanceについて、5/8の午前中くらいに4人でワイワイ議論します!楽しみ〜https://t.co/5nDiH7vSlp #web24
— shqld✌️ (@shqld) May 1, 2021
好きなことを仕事にするということ
この記事は SHIROBAKO Advent Calendar 2020 の15日目です.
今年は劇場版が公開されたと思ったのも束の間,その前後から他作品の公開延期や映画館の休館などが相次ぎ,周囲の状況も気にしながらいつ見に行けるのかとハラハラさせられた一年でしたね.今回はその劇場版から,丸川元社長のセリフについて考えてみたいと思います.
みゃーもりが思い悩んで丸川元社長に会いに行ったとき,みゃーもりに次のような言葉を投げかけます.
「好きなだけでは続けていけない。作ることで何をしたいのか考えないと。」
 (画像は劇場版『SHIROBAKO』本予告より引用)
(画像は劇場版『SHIROBAKO』本予告より引用)
最初に劇場版を見たとき,最も印象に残ったのがこの言葉でした.
私は Web エンジニアとして働いていますが,もともとプログラミングを始めたのは13歳の時で,楽しさにハマってずるずる続けた結果そのまま仕事になってしまったパターンです.社内の目標設定でその四半期にやることは決定できても,数年後に自分がどうなっていたいのかという中長期な目標は曖昧で明確なものがありません.直近ではパフォーマンスチューニングに興味を持ち,ありがたいことにそれを専任でやるチームを任せてもらっています.楽しくて好きなことを自由にできる環境をいただいているのでとても幸せなことなのですが,そうであるからこそ丸川さんの「作ることで何をしたいのか考えないと」という言葉が深く刺さったのでした.
みゃーもりは TV アニメ24話で,「これからどうしたいのか」という問いに対して「アニメを作ることとアニメを作る人が好きだから,アニメを作り続けたい」という思いを発見しました.劇場版のこの言葉は,それをさらに一歩進めるものといえそうです.劇場版でのみゃーもりは入社6年目でラインプロデューサーを任され,厳しいことや辛いこともはじめの頃の比ではなく襲いかかってきます.そんなときに最後までやり抜く力を発揮するには,「好き」という気持ちだけでは足りず,「成し遂げたいこと」「届けたいこと」というより強く根源的な思いが必要だと諭してくれているのではないでしょうか.
「サービスを速くしてより快適な体験をユーザーに届けたい」「界隈で有名になりたい」「技術力を上げてたくさん稼ぎたい」... 「何をしたいのか」という部分は依然として私の中で定まりきっていないところがあります.常に目標に向かって走り続けるのは疲れてしまいますが,せめて「何をしたいのか」という軸だけでも引き続き探していきたいと思います.
![劇場版SHIROBAKO 通常版 [Blu-ray]](https://m.media-amazon.com/images/I/41EQPRaX5GL._SL500_.jpg "劇場版SHIROBAKO 通常版 [Blu-ray]")
- 発売日: 2021/01/08
- メディア: Blu-ray
伊豆大島へ一週間ワーケーションに行ってきた話
東海汽船が出した,5万円で伊豆大島に7泊8日できるリモートワークプラン
https://www.tokaikisen.co.jp/news/134866/www.tokaikisen.co.jp
(リンク先が消えてしまっているようなのでアーカイブ)を使って10月最終週にワーケーションしてきたので,記録がてらどんな感じだったかを書いてみようと思います!
残念ながら執筆時点でこのプランはもう完売御礼とのことですが,そもそもワーケーションってどうなの?いろいろなところがプラン出してきてるけどどんなことに気をつけて選べばいいの?という疑問にも答えていきます.
伊豆大島とは?
伊豆大島は東京都の伊豆諸島のうち,最も本州の近くにある大きな島です.自分も今回申し込むまで知らなかったのですが,竹芝桟橋からジェット船で2時間足らずと割と気軽にいくことができる島でもあります.
椿と明日葉が有名で,大島椿の黄色いパッケージを見たことがある方もいるのではないでしょうか?
他には,最近ブラタモリでも紹介された三原山という火山がよく知られています.
そこそこ活発に活動している活火山で,直近では1986年に大きな噴火を起こし全島避難したそうです.
プランの詳細
今回宿泊したのはそんな三原山の7合目あたりにある大島温泉ホテルというホテルです.
竹芝桟橋からの往復ジェット船と朝夕の2食つきで5万円,GoTo キャンペーン適用で 32,500 円 + 地域共通クーポン 8000 円だったので実質交通費込み一泊3,500円で泊まることができました!
島への往路
浜松町駅から徒歩8分,独特の形状をしている竹芝桟橋から出発しました.

2階建のジェット船に乗り込みます.

中はこんな感じ.

出発前に撮った桟橋周辺の様子です.天気に恵まれました!

ジェット船は海水を船の下から吹き出すことで船体を浮かせながら航行するため波の影響をほとんど受けず,しかも大島への航路は大半が東京湾内なので全然揺れませんでした.波から波へとジャンプするいわゆる高速船を思い浮かべていたので驚きました.
うとうとしているうちに予定どおり2時間弱で大島に到着です.



ホテルの様子
ホテルは年末まで外装工事を行っており,ぐるりと足場が取り囲んでいる状況でした.

本来は三原山が綺麗に見えるであろう食堂にも足場がかかっていたので,この辺りも今回の格安プランを提供するきっかけになったのではないかと思います.

お部屋は純和室です.ここにも足場が設置されています.


お食事
このプランのすごいところは二食付きなところです.ワーケーションプランでは大抵安い代わりに食事なしなことが多いからです.例えば星野リゾートに一泊3000円で泊まれる!と話題になった OMO7 旭川 も食事なしです.
しかも,内心「安いプランだから通常の場合よりも簡素な食事になるんだろうな...」と思っていましたがそんなことはなく,他の宿泊客と変わらないクオリティの食事が出ました!
海鮮や明日葉を椿油で揚げて食べる椿フォンジュとサザエご飯


刺身舟盛り

金目鯛のしゃぶしゃぶ

金目鯛の煮付け

朝食も毎朝豪華でした!

毎日ちょっとづつメニューが変わるので飽きませんでした.
また,仕事するにあたって気になる昼食ですが,フロントでお弁当を予約することができたため山を降りて調達する必要もありませんでした(別料金700円).

工事をしている職人さんにも出しているのでは?と思ってしまう山盛りの弁当だったので,座り仕事のエンジニアにはちょっと多い気もしましたが,朝晩が基本的に海鮮なので肉が入っている弁当はまた新鮮な気持ちで食べられました.
仕事環境
さて,本題の仕事環境ですが,まず気になるのはネットワーク環境です.
出発前に
来てみてわかったこととしては、Wi-Fi激弱。
— アヤ (@aja_3204) October 12, 2020
すぐ行方不明になるので、モバイルデータ通信機能を備えていない端末でくるとワーケーションは無理ぽ。
Wi-Fi完備はちょっと看板に偽りありだなぁ。#伊豆大島 #ワーケーション #大島温泉ホテル
ちなみにこんな感じ。激弱どころか死んでいる上にオープンネットワークな件。 pic.twitter.com/buKnHSVDjE
— アヤ (@aja_3204) October 12, 2020
というツイートを見ていたので心配していました.ただ,このツイートからは単に WiFi の電波が弱いだけとも読めるので,部屋ガチャによってはルーターに近く安定して通信できる可能性もあります.
自分が泊まった部屋は 208 でしたが,

の写真からもわかるとおり扉を出てすぐのところに WiFi ルーターがあるというかなり高ポジションをツモることに成功しました.
ではネットワークが安定していたのか?というとそれが微妙なところで,
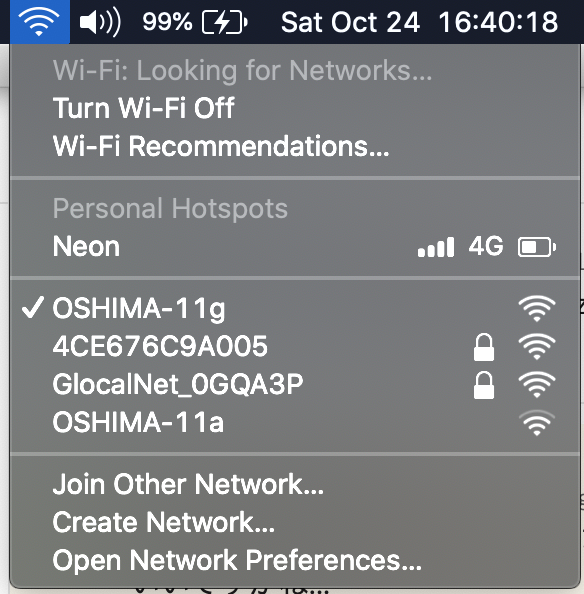

のとおり電波は強めで運がよいと 32 Mbps くらい出るときもありました.
しかし,接続状況はわりと不安定で1時間安定して繋がることもあれば10-15分に一回途切れることもあり,特にルーターから離れる部屋の奥で顕著でした.Zoom での会議もできなくはないのですが頻繁に映像や音声が止まるため,安心してミーティングができるという環境ではありませんでした.
また,和室なのでどうしても座椅子での作業となって腰や首が辛いという問題もあります.テレビの下が収納になっていたので広縁の椅子を持ってきてマシな作業スペースを作ることもできましたが,前述のネットワークの問題で結局ほとんど使わずじまいでした.

ネットワーク環境さえよければ HDMI ケーブルを持ってきて TV をディスプレイ代わりにできた可能性もあるだけに残念です...
ただ,一人で作業している分には部屋に篭る必要もないですし,大自然に囲まれているという利点を生かして気分転換も気軽にできます.
ロビーに PC を持っていって作業したり...


行き詰まったら温泉に浸かって三原山を眺め,
(上記画像は 大島温泉ホテル 公式サイト からの引用)
風呂上がりにアイスを食べたり...

朝はホテルのすぐ裏から三原山山頂まで続いているトレッキングコースを散歩して,爽やかな気持ちで仕事を始められました.


最終日はちょっと早起きして,日本唯一の砂漠「裏砂漠」を散策してから部屋に戻って朝会に出席しました!


2枚目で遠くに見えるのが温泉ホテルです.ちなみにこの裏砂漠はモバイル回線の電波がフルで立っていたので,ここに PC を持ち込んで仕事をすることも不可能ではないと思います(国立公園の特別保護地区に指定されているので派手なことはできませんが).
清掃面では,仕事中に掃除に来られてしまうと困るので基本的に Please Do Not Disturb を扉にかけていましたが,毎日扉の脇に替えのタオル,浴衣,水,アメニティ,そしてお菓子まで補充して置いていただけたので快適に滞在できました.

観光
土曜日の到着だったので翌日の日曜日と,余っていた代休を取った水曜日の計2日間を観光に充てました(同じプランで滞在していたと思しき他の人はミーティングだけ出てもっと観光している人もいたようです;)
自転車を借りて海辺を漕いだり

地層切断面を見にいったり

名物べっこう寿司を食べにいったり

山頂までトレッキングにいったり




しました!
ワーケーション滞在先の選び方
シティホテル,ビジネスホテル,温泉宿などいろいろなところがワーケーション・リモートワークプランを提供し始めており,今後もじわじわとワーケーションは広まっていくのではないかと思います.今回自分は東海汽船のリモートワークプランを Twitter で発見してから即申し込みをしてしまいましたが,この経験を踏まえてどのような観点で滞在先を選べばよいかまとめてみました.
WiFi 環境
東海汽船のアナウンスには 館内Wi-Fi設備も充実しております と書かれていました.わざわざ「リモートワークプラン」と銘打って出すくらいだから高速で安定した回線を用意したのだろう,と鵜呑みにしてしまいましたが,蓋を開けてみるとビデオ会議をするには厳しい環境でした.
- 全ての部屋,部屋のどの位置からでも安定して接続できるのか
- 複数人がビデオ会議をしても遅延が起きない高速な回線が用意されているのか
などは仕事をするには重要な観点ですが,公式サイトには明記されていないことがほとんどです.もともとビジネス用途を多く受け入れてきたシティホテルやビジネスホテルはネットワーク品質も安定している可能性が高いですが,この度のコロナ禍をきっかけに新しく始めた温泉宿などを検討する際には,直接ホテルに問い合わせたり口コミを調べるなどして情報収集に努めた方がよいでしょう.
和室か洋室か
エンジニアなど PC に向かってキーボードを叩くことが主な仕事の場合,和室は作業にあまり向いていないと言えます.テーブル・椅子など快適な作業空間が確保できるのか,事前に館内設備や間取りを調べておくことをお勧めします.
都会か田舎か
都会であれば食事の調達に困りませんし,急な出費など何かあった場合でも対応できる可能性が高くなります.一方で田舎は自然豊かでリフレッシュできますが,利便性には劣ります.食事の有無と絡めて目的地を考えるとよいでしょう.
仕事の予定を見極める
今回は重要なミーティングが詰まっているという状況ではなかったため,ネットワークの問題もさほど影響を受けずに仕事を進められました.また,極端な話ですが急に出社の必要が出た場合でも旅先ではなかなか難しくなります.諸問題が発生しても影響を抑えられるよう,あまり多忙な時期は避けた方がよいでしょう(問題が起こらなくても現地に行くと観光したくなりますし).
持っていくと便利なもの
持っていったものと持っていけなかったものがありますが,あると便利と感じた品々です.
- モバイルルーター,あるいは充分な通信量の余裕があるモバイル回線を契約しているテザリング可能なスマホ
- 現地で用意されているネットワーク環境に問題があった場合にバックアップとして利用できます
- HDMI ケーブル
- 備え付けのテレビをサブディスプレイとして使うことができるようになります
- 外付けキーボードとトラックパッド (またはマウス)
- MacBook Pro のディスプレイの位置を調節して作業ができます
- イヤホン
- 宿の壁が薄い可能性があるので,イヤホンをしてミーティングに出ると安心です
おわりに
しょっちゅう映像が止まる状況にも協力していただいた同僚には感謝しきれません.本当にありがとうございました!
観光も仕事も中途半端になるのではないかと初めはワーケーションに懐疑的でしたが,結果として今回のワーケーションはとてもいい気分転換になりました.GoTo トラベルが残っているうちに試してみてはいかがでしょうか?